This is the seventh article for the website.
In this blog post, I will be writing a paper summary on A deep learning framework for segmentation of retinal layers from OCT images by Karthik Gopinath, Samrudhdhi Rangrej and Jayanthi Sivaswamy. We will be employing the same approach as before.
Before reading any research paper, it becomes important to ask the important question:
1) What problem is the entire field trying to solve?
Ans. OCT[Optical coherence tomography] is used to study the structural composition of tissues at micrometre resolutions. Dividing the tissues into different layers and study of the intermediate regions between the layers can help us tackle several eye related diseases.But, this process requires the use of tedious and accurate layer markings. The need of the hour is an automated process of marking the layers.
2)Summary of the background
Ans. Automating the layer segmentation tasks also brings with it many challenges like speckle noise,vesel shadows and variation in the orientation of layers. To handle these new issues hindering our task of automation, we have to perform pre-processing to remove this unnecessary data. For preprocessing, we use methods like median filtering, block matching, 3D filtering,etc. The caveats with using these methods is the high amount of tuning required for each of them. Presence of anomalies in the eye will also require a separate amount of tuning. TO counter this problem, the author proposes the use of Deep Neural Networks and Binary LSTMs. The advantage of these methods is the low amount of pre-processing.
3)Identify specific questions.
Ans. The author wants to find an answer to the question: Are DNNs and BLSTMs better than its predecessors in the process of automated layer segmentation of the eye.
4) Identify the approach.
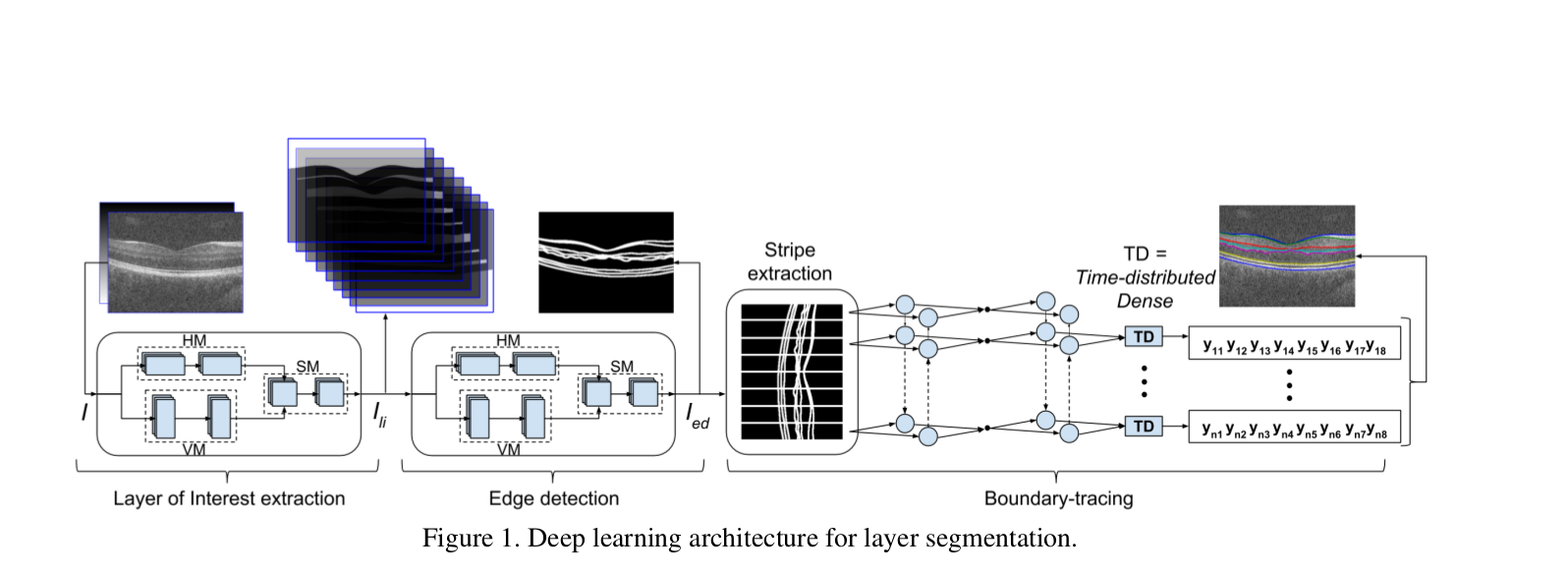
Ans. To avoid noise accompanying the data, we don’t apply edge detection directly to the images to find the Location of Interest. Instead, the authors have passed the images through a cascade of layers to generate the images of our interest. We employ the following approach:
1) Layer of Interest(LOI) extraction:
I/P: A stack of OCT images + position cue image ![]() This is passed through 2 modules parallelly: Horizontal Module[HM] and Vertical Module[VM]. The purpose of these 2 layers is
This is passed through 2 modules parallelly: Horizontal Module[HM] and Vertical Module[VM]. The purpose of these 2 layers is
1) Learn if there is any problem present in the eye[Horizontal Module] by comparing horizontal neighbour images.
2) Learn the difference between different layers [Vertical Module].
The outputs from both these layers are combined and sent to the Square Filter Module[SM] which generates the final output of this step.
O/P: LOI ![]() with 9 layers[ 7 layers +
vitreous cavity + choroid].
with 9 layers[ 7 layers +
vitreous cavity + choroid].
2) Edge detection:
I/P: ![]() This is also passed through a similar trilateral modules[HM, VM and SM].
HM learns the horizontal orientation, VM learns the vertical orientation and SM combines both the outputs to give a final image
This is also passed through a similar trilateral modules[HM, VM and SM].
HM learns the horizontal orientation, VM learns the vertical orientation and SM combines both the outputs to give a final image
![]() , covering all the kinds of orientation.
, covering all the kinds of orientation.
O/P: ![]()
3) Boundary tracing:
I/P: ![]() This step employs the use of BLSTMs. We calculate 8 boundary co-ordinates
This step employs the use of BLSTMs. We calculate 8 boundary co-ordinates ![]() is shifted right and left twice:
(
is shifted right and left twice:
(![]() (x - k,y); k
(x - k,y); k ![]() {-2,-1,0, 1,2}) and stacked such that each column is aligned with its neighbours in the 3rd dimension. Each column is known as
**stripe**. Each stripe is passed through a BLSTM. We learn boundary co-ordinates from the left and right stripes respectively and
estimated
{-2,-1,0, 1,2}) and stacked such that each column is aligned with its neighbours in the 3rd dimension. Each column is known as
**stripe**. Each stripe is passed through a BLSTM. We learn boundary co-ordinates from the left and right stripes respectively and
estimated ![]() helps in tracing the 8 boundaries of the image.
helps in tracing the 8 boundaries of the image.
5) Methods:
6)Results:
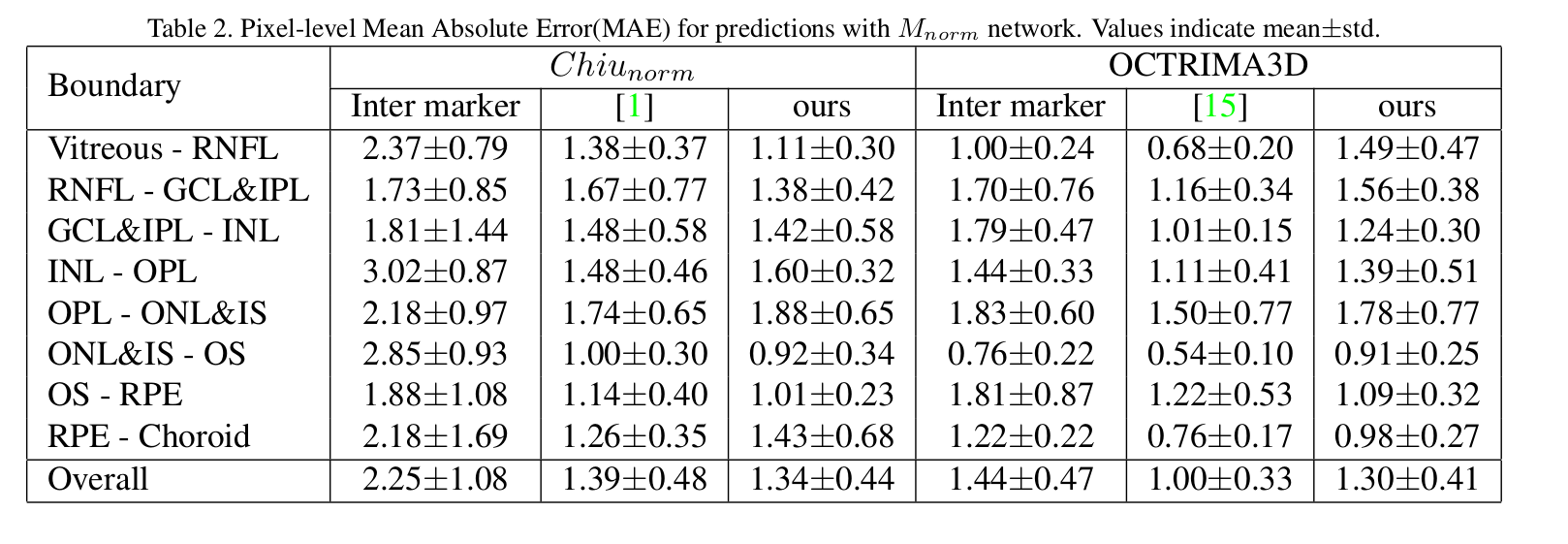

7) Determine whether the results answer the specific questions?
Ans. The results show that the author has been able to achieve noticeable accuracies on benchmark datasets.
I would love to hear feedback on the article. Any suggestions or mistakes can be pointed out in the comments below.